
圖片來源: https://pixabay.com/en/books-spine-colors-pastel-1099067/ 和 https://pixabay.com/en/math-blackboard-education-classroom-1547018/
在上一篇([06]建立Hadoop環境 -下篇)把hadoop pseudo-distributed mode整個建立了起來,在這個過程中有透過 jps看到啟動的時候有5個process:
NameNode
SecondaryNameNode
ResourceManager
NodeManager
DataNode
這些process分別是yarn和HDFS執行起來的process,其中Master會有前 3個而slave有後 2個
這篇將會對於這幾個問題做一些介紹。
這篇提到的架構屬於Hadoop 2.x 版本的內容,Hadoop 3 之後有所變動。
這篇將延續上篇的環境,把Hadoop建立上去,並且讓Hadoop跑一個hello world的範例。
同步發表於我的部落格:http://blog.alantsai.net/2017/12/data-science-series-07-deeper-look-at-yarn-and-hdfs-in-hadoop.html (部落格的格式會漂亮一些,ithome不支援html好不方便)
在介紹幾個jps之前,需要了解Hadoop Clusted的架構。
Hadoop屬於Client/Server架構,基本上會有 一個Master, 多個slave。
因為Master很重要,所以2.x版本可以為master做High Availability和Federation。
在上一篇建立的屬於 pseudo-distributed mode,換句話說Master和Slave都是同一台,所以才看到了5個process。
以下圖來說,是一個Master配上兩個Slave。master和slave裡面又可以分開兩層:MapReduce 和 HDFS 層
不同層的內容。來源:http://saphanatutorial.com/how-yarn-overcomes-mapreduce-limitations-in-hadoop-2-0/
注意,這邊的MapReduce層用的是Hadoop 1.x 的名稱。以2.0來說應該是YARN層。
先來看看上面那層,可以看到:
JobTracker - 在Master
TaskTracker - 在Slave
當一個工作被記錄的時候(例如呼叫WordCount.jar),會先進入到 JobTracker,再由JobTracker去 切割分派給 slave的 TaskTracker去做執行。最後TaskTracker在回報結果到JobTracker裡面。
job分派情況,來源:http://saphanatutorial.com/mapreduce/
看到這邊,或許會奇怪,為什麼jps裡面沒有JobTracker和TaskTracker?原因是,JobTracker和TaskTracker是 MapReduce Layer層的內容,而Hadoop 2.0加上了YARN,因此在jps看到的是 ResourceManager和 NodeManager。
簡單來說,可以理解成為:
JobTracker - ResourceManager
TaskTracker - NodeManager
Port 8088是ResourceManager的UI界面
因此可以用瀏覽器看到目前:
有幾個cluster - 幾個slave
有哪些工作
工作的執行情況
因此,run起來之後可以用這個來檢查目前情況。
8088的呈現畫面
基本上HDFS層和MapReduce層有一樣概念,不過這一次變成是儲存資料層的分散式儲存。
NameNode - 在Master
DataNode - 在Slave
NameNode會記錄檔案分散在那幾個DataNode裡面。並且會透過replicate的方式把資料分成N份(一般是3份)儲存在不同DataNode達到檔案高可用性。
以下圖來說,檔案被拆成了兩份:A和C,會自動被儲存在DataNode1~3,因此如果DataNode2掛掉了,NameNode會知道,並且 變成由DataNode1和DataNode3來處理。
NameNode和DataNode的關係。來源:https://www.quora.com/Explain-what-is-NameNode-in-Hadoop
上面介紹了NameNode和DataNode,那麼Secondary NameNode呢?
Secondary NameNode用來提供一個Checkpoint輔助NameNode處理資料。
因此Secondary NameNode不是備份用,因此為了避免誤會有時候會成為Checkpoint Node。
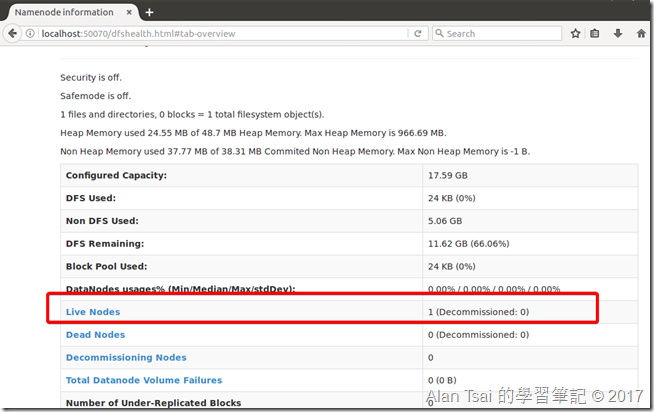
Port 50070是NameNode的一個web UI界面
在這個界面裡面可以看到DataNode有幾台,並且有幾台死掉了等資訊。
50070的畫面
希望透過這篇對於底層的jps process有些了解,並且對於hadoop的cluster更有感覺。
在下一篇,將會回到實際操作的部分,不過這次實際建立一個完整的cluster。Master那台本身是一台slave然後建立另外一台純粹是slave的機器。
工商服務
今年的團隊機制不知不覺就集合了10位隊(坑)友 - 大家幫忙多多關注別不小心我們就gg了 XD
** 一群技術愛好者與一名物理治療師的故事 提醒著我們 千萬不要放棄治療 **
沉浸於.Net世界的後端工程師,樂於分享,現任台中Study4成員之一。除了程式以外,就愛看小說。
歡迎有任何問題或者建議都可以告訴我,可以再以下找到我:
部落格:Alan Tsai的學習筆記
我的Linkedin
我的粉絲頁
我的github
我的Slideshare
我的Twitter







 iThome鐵人賽
iThome鐵人賽